(BKS15) Dictionary Learning and Tensor Decomposition via the Sum-of-Squares Method
Posted: 2016-08-30 , Modified: 2016-08-30
Tags: dictionary learning, tensor, sparse coding
Posted: 2016-08-30 , Modified: 2016-08-30
Tags: dictionary learning, tensor, sparse coding
Theorem. Given \(\ep>0,\si\ge 1, \de>0\) there exists \(d\) and a polytime algorithm that given input
outputs with probability \(\ge 0.9\) a set \(\ep\)-close to columns of \(A\).
Note on running time:
Given noisy version of \(\sumo im \an{a^i, u}^d = \ve{A^Tu}_d^d\), recover \(\{a^1,\ldots, a^m\}\).
Theorem (Noisy tensor decomposition). For every \(\ep>0,\si\ge 1\) there exist \(d,\tau\) such that a probabilistic \(n^{O(\ln n)}\)-time agorithm, given \(P\) with \[\ve{A^T u}_d^d - \tau \ve{u}_2^d \preceq P \preceq \ve{A^Tu}_d^d + \tau \ve{u}_2^d,\] outputs with probability 0.9 \(S\) that is \(\ep\)-close to \(\{a^1,\ldots, a^m\}\). (\(\preceq\) means the difference is a sum of squares.)
Note this allows significant noise since we expect \(\ve{A^Tu}_d^d\sim mn^{-\fc d2}\ll \tau\).
Take \[ P = \EE_{i} \an{y_i, u}^{2d}.\]
SoS Algorithm: given \(\ep>0, k,n,M\), \(P_1,\ldots, P_m\in \R[x_1,\ldots, x_n]\) with coefficients in \([0,M]\), if there exists a degree \(k\) pseudo-distribution with \(P_i=0,i\in [m]\), then we can find \(u'\) satisfying \(P_i\le \ep, P_i\ge -\ep\) for every \(i\in [m]\) in time \((n\polylog\prc{M}{\ep})^{O(k)}\).
(Proof: This is a feasibility problem. Use ellipsoid method.)
Steps
Idea: If not correlated, then \(P(u)\) is small. The inequalities can be turned into polynomial inequalities provable by SoS.
Theorem (Noisy tensor decomposition, 4.3). There is a probabilistic algorithm that given
If \(U\) correlates well with \(A\), then \(U\) correlates with some column of \(A\).
Lemma 6.1. Given
there exists a column of \(A\) such that \(\wt \E \an{c,u}^k \ge e^{-\ep k}\), \(\ep=O(\de + \fc{\ln \si}{d} + \fc{\ln m}k)\).
Now we analyze the algorithm to “sample pseudo-distributions”: given a PD that correlates with a vector, find a vector close to it. We prove:
Theorem 5.1. The “sample pseudo-distributions” algorithm, given
outputs \(c'\in \R^n\) with \(\an{c,c'}\ge 1-O(\ep)\) with probability \(2^{-\fc{k}{\poly(\ep)}}\).
We are given \(c\) such that \(\wt E\an{c,u}^k \ge e^{-\de d}\) (high correlation) and we want that \(c\) to be a value of \(v\) that makes (the quadratic form) \(v\mapsto \wt \E W(U) \an{v,U}^2\) large. In fact, what we want is that when normalized so the sum of the eigenvalues is 1, the singular value corresponding to \(c\) is close to 1.
There are 3 parts. (a) We need to understand how “renormalization” of pseudo-distributions works. (b) We need to show that for our choice of \(W\), we have with some probability a lower bound for \(\wt \E W(U) \an{c,U}^2\). This is the hardest part. (c) We need to show that \(c\) is close to the singular vector (which we output). (I think (c) is in essence a matrix/eigenvector perturbation result, but it’s cloaked in the language of SoS here—unravel!)Lemma 5.2. Let \(U\) be a degree-\(k+2\) pseudo-distribution over \(\R^n\) with \(\ve{U}_2^2=1\) and such that there exists a unit vector \(c\in \R^n\) such that \(\wt \E\an{c,u}^k \ge e^{-\ep k}\). \(W=\rc{M^{k/2}} \prod_{i=1}^{k/2} w^{(i)}\) where \(w^{(i)}\) are iid draws from \(w=\an{\xi,u}^2\), \(\xi\sim N(0,I_n)\). Then with probability \(2^{-O\pf{k}{\poly(\ep)}}\), \(\wt \E\an{c,u}^2W \ge (1-O(\ep))\wt \E W\).
(?? Discrepancy between \(k\) and \(k+2\).)(Take \(M=\rc{\ep}\ln \prc{\ep}\).) This is almost what we want, except that we conditioned on \(\an{c,\xi}\ge \tau_{M+1}\) and that this is an inequality about absolute values.
To get rid of the conditioning, note that the event \(\forall i, \an{\xi^{(i)},c}\ge \tau_{M+1}\) has probability \(2^{-O(kM^2)}\).
To get the result with not-too-small probability, rearrange as \[ O(\ep) \EE_W \wt \E W \ge \EE_W \wt \E W - \EE_W \wt \E W\an{c,U}^2, \] bound second moments \(\E_W(\wt \E W)^2\), and use(From degree 2 p.d. to a vector)
Lemma 5.4. Let \(c\in \R^n\) be unit and \(U\) be a degree-2 p.d. over \(\R^n\) satisfying \(\ve{U}_2^2=1\). If \(\wt \E\an{c,U}^2 \ge 1-\ep\), then letting \(\xi\) match the first two moments of \(U\) and \(v=\fc{\xi}{\ve{\xi}_2}\), we have \(\Pj[\an{c,v}^2 \ge 1-2\ep] =\Om(1)\).
Proof. Again use Lemma 5.3, just check \(\E\ve{\xi}_2^t \le O(\E\ve{\xi}_2^2)^2\).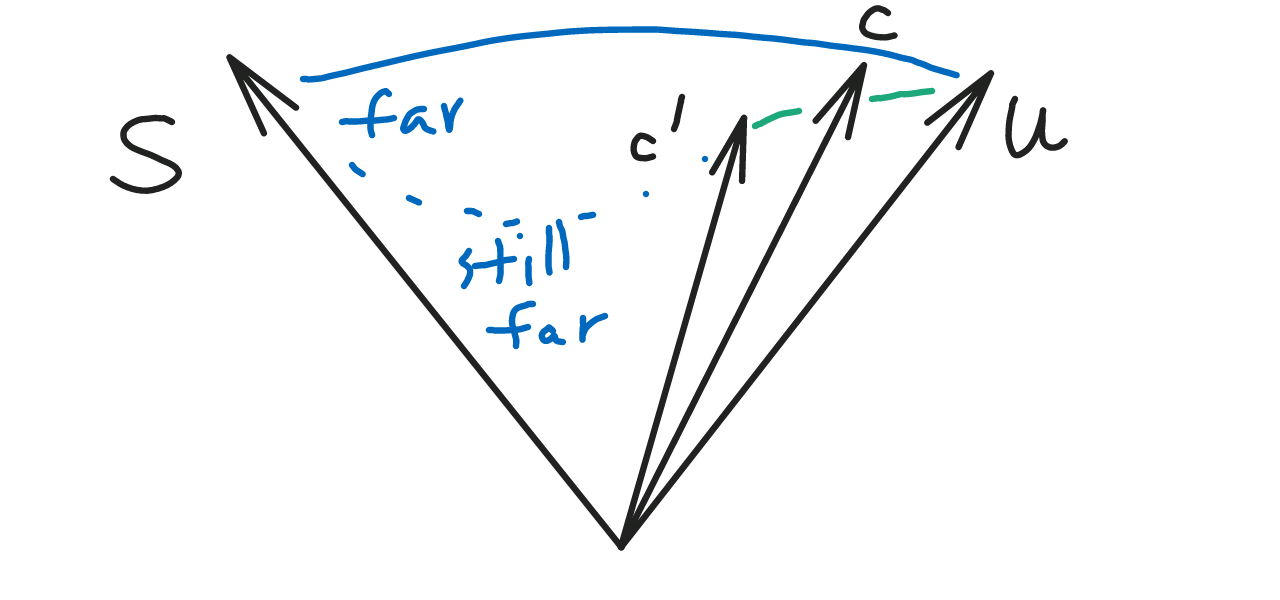
The algorithm below, given
outputs in time \(n^{\fc{d+\ln m}{\ep^{O(1)}}}\) a set of vectors \(\ep\)-close to \(A\).
Take \(\wt O \fc{n^{2d}}{\tau^2}\) samples \(x^{(i)}\) and apply noisy tensor decomposition to the polynomial \[ \EE_i x^{(i)} \an{Ax,u}^d \] where \(d\ge D:=O(\ep^{-1}\ln \si)\).
Note that \(\an{Ax,u}^d\) is the polynomial (\(n\)-ic form) corresponding to the tensor \((Ax)^{\ot d}\), just as \(u^T vv^Tu = \an{u,v}^2\) is the quadratic form corresponding to the matrix \(vv^T\).
Proof.
(Calculate expectation) Lemma 4.5. If the distribution of \(x\) is \((d,\tau)\)-nice and \(A\) is \(\si\)-overcomplete, then \[\EE_x \an{Ax,u}^d \in \ve{A^Tu}_d^d + [0,\tau \si^dd^d \ve{u}_2^d]\] (where inequalities are in the SoS sense).
Proof. Expand the sum as \(\sum_\al x_\al (A^Tu)_\al\). For \(\al=[i,\ldots, i]\) we get the term \((A^Tu)_i^d\). For the other terms, \[\begin{align} 0 &\le \sum_{\al \in [n]^d,\al \ne [i,\ldots, i] }(\E x_\al) (A^Tu)_\al \\ & \le \tau \sum_{\al \in [n]^d,\al \ne [i,\ldots, i] } (A^Tu)_\al \\ & \le \tau d^d\sum_{\be \in [n]^{d/2},\be \ne [i,\ldots, i] } (A^Tu)_\be\\ & \le \tau d^d\ve{A^Tu}_2^d \le \tau \si^d \ve{u}_2^d. \end{align}\] (The \(d^d\) bound is crude; this is not the bottleneck.) Note the lower inequality depends on there only being even nonzero terms.Use noisy tensor decomposition. Check parameters. There we needed \(d \ge D=O(\rc{\ep}\ln \si)\). We need \(\tau\le \fc{\ep}{\si^DD^D}\). (Errata? The value of \(\tau\) is different than in the theorem.)
This means polytime for fixed \(\ep\). Note to get \(\rc{\ln n}\) closeness (ex. for initialization of an iterative DL algorithm), we need quasipolytime, \(n^{O(\ln n)}\).
The bottleneck is the \(\ln m\) in Lemma 6.1, where we used averaging to conclude that if \(U\) has large correlation with \(A\), then \(U\) has large correlation with a column of \(A\).
| Before | Now |
|---|---|
| 5.2 | 7.2 |
| 5.1 | 7.1 |
| 6.1 | 7.3 |
To summarize the previous argument, we show our distribution of \(W\) satisfies inequalities given in 5.2, and then use reweighting to obtain that \(u\) is correlated with some column in 5.1. Now we use the weak lemma 6.1 which recovers that column, with \(\ln m\) loss.
If we weaken the conclusion of 6.1, then we can hope that 6.1’, i.e., 7.3, doesn’t have a \(\ln m\) in the place we care about. Then we need 5.1’, i.e., 7.1, to work with these weaker conditions. Sparsity allows us to weaken the conditions on correlation, provided we have better bounds information about the distribution \(W\) that we choose.
(Not quite: 5.2 was a lemma for 5.1. 7.1 is a lemma for 7.2, we use 7.1+5.1 to get 7.1.)
Specifically, the condition on the p.d. \(U\) (degree \(2(1+2k)\)) is (7.2) \[ \wt \E\an{c,U}^{2(1+2k)} \ge e^{-\ep k} \wt \E \an{c,U}^2, \qquad \wt E\an{c,u}^2\ge \tau^k. \] This is easier to satisfy: the \(\rc m\) that causes problems is moved to the second inequality (as long as we have sparsity \(\tau^k\le \rc m\) we are OK). The second inequality is true if sparsity is \(\tau\) (CHECK!!). \(k\) no longer needs a factor \(\rc{\ln m}\) in the denominator to satisfy this.
Note 5.2, 5.1 don’t mention the sparsity at all, while 7.2, 7.1 mention \(\tau\) which will be related to the sparsity.
Some changes: instead of reducing from degree \(k\) to \(2\) we reduce from degree \(\approx 4k\) to \(2k\). (??)
So how does the algorithm work now, given that our assumption is (7.2) rather than a bound on \(\wt \E \an{c,u}\)? 7.1 has the following inequality on \(\ol W= \E_WW\), (7.1): \[\an{c,U}^{2(1+k)}\preceq \ol W \preceq (\an{c,U}^2 + \tau\ve{U}_2^2)^{1+k}.\] Using this, get an upper bound on \(\wt \E \ol W\) and lower bound on \(\wt \E \an{c,U}^{k}\) to get a lower bound on \(\wt\E \ol W\an{c,U}^{2k}\): \[\wt \E \ol W\an{c,U}^{2k} \wt \E \ol W \ge [\wt \E(\ol W \an{c,U}^k)]^2.\]
The bound on \(\ol W\) comes from sparsity. Take \(W=\prodo i{k/2-1} \an{y_i=Ax_i,U}^2\). \(\ol W\) does not actually satisfy (7.1); it does after reweighting by \(\prodo i{k/2-1} x_{i,1}^2\). (This is a distribution over polynomials. Take the probability that \(\prod \an{Ax_i,U}^2\) is chosen and multiply it by \(\prod x_{i,1}^2\) and normalize the probabilities. (Not multiply the polynomial.)) Consider \(c\an{Ax,u}^2\) reweighted by \(x_i^2\); expand and use sparsity to get a nice bound on expectations.
This is much better than the previous analysis on \(W\)! It actually seems to take into account some kind of concentration…
Final theorem is 7.6.
(Q: can you adapt something like this for NMF?)
Can we do better if we use polynomial concentration?↩